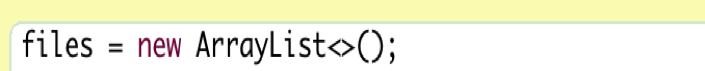In Java, abstraction is often used to manipulate date. Collection is an abstraction in which data are grouped together for us to arrange and manage. The collection can be huge, or it can be empty. We can add, remove, or get items in the collection. In a programmer’s perspective, collection can be regarded as a class, and the items in it can be objects. As we make changes to the collection, we are calling methods. As an example of collection, the names of all students in the school may form a collection.
Library Class & ArrayList
In java, there are many classes that are proven to be useful for developer, which are stored in the class libraries. The instances of library classes are constructed using new.
ArrayList is a class imported from a library class in java.
Importing the ArrayList from the package “java.util.”
The line above should be written in the beginning of the program. The “java.util” is called a package. By importing the ArrayList class, we can use it in the following program.
Generic Classes
ArrayList is a type of collection, which is static and very simple. To instantiate a new variable that has the class type “ArrayList,” we add this line to our program:
Here, the new ArrayList is stored in the field “files.” The word “String” means that this ArrayList is a collection of Strings. We use the diamond notation “<>” to specify the type of elements stored in the ArrayList.
Classes like ArrayList are called generic classes. These classes need parameters that have a second type. For example, the elements in the ArrayList may be String, integer, etc. Not limited to primitive data type, we can use class type to instantiate the objects in the ArrayList.
ArrayList
Specifically for ArrayList class, there are many methods that are under this class. In our course, we only learned four types of them, which are add, size, get, and remove. We use dot notation to use these methods. For example, if we want to use these methods, we use these codes:
files.remove(index);
files.add(item);
int number = files.size();
return files.get(index);
Since the the ArrayList is static, it has a temporarily fixed size (if not changed by other methods). The size of an ArrayList is the total number of items in the ArrayList. Moreover, each item has an Index. It has to noted that the first item has the index “zero.” Therefore, the last item’s index is “size-1.” Therefore, when we use the remove or get method, we should be careful about this. Here is an example:
Here, I make sure that the index is not out of range.
In this example, if we use a index that is not in the range, there will be an error called “IndexOutOfBoundsException“. This error is a called an index-out-of-bounds error.
It’s also important to know that the add method automatically add the new item to the end of the ArrayList.
Exercises
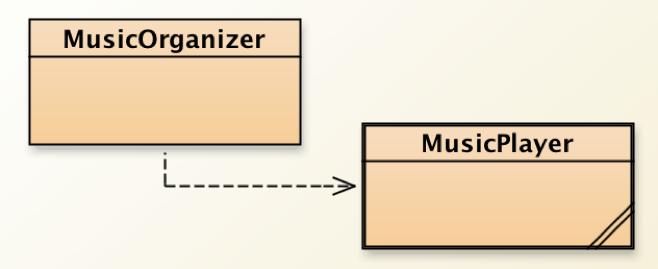
The exercise 4.17 asked us to try to play around with the music player.
This class diagram shows that the Music Organizer uses the object instantiated from the class MusicPlay.
Firstly, I created an object called MusicOrg1. Then I used the method addFile(String filename).
I entered the file’s location as the argument.
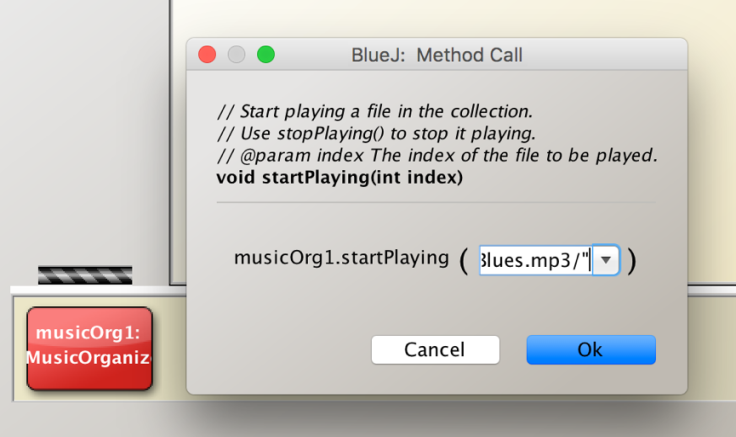
Then I called the startPlaying(int index) method.
The code of startPlaying Method, which is actually from the MusicPlayer class.
After that, It works! I heard the music start playing. Then I tried stop playing and the music stops. How amazing this program is!
Complexity/simplicity – the amount of effort required to find a solution to a problem. A simple product will save a lot of time and effort for the devices and users.
Effectiveness – how does the system achieves the predefined level of performance. The product should be effective enough to meet the users’ needs.
Efficiency – the time required for the system to perform certain tasks. product with high efficiency can certainly improves the readers experience.
Error – the amount and type of error, and the time required to recover from the error. Once there is a error, there need to be some recovery plan or guidance to help the users to fix it.
Learnability – time taken for the user to successfully use the system for the first time. Therefore, step by step user guide should be included in the product. Also the design should be clear.
Memorability – time and steps used by the user as they have not use the system for a period of time. To make the product more memorable, the icons and symbols should be reasonable and straightforward.
Readability/comprehensibility – the speed that the users process the information provided by the system. It is usually related to the design of the presentation of the information (for example, the selection of font size).
Satisfaction – the extent to which users like the product (aka. the users’ attitude towards the product).
Real-life Usability Problems
For different products, their might be different types of problems.
For PCs, the visual design is not aesthetically good so that some users do not like it (satisfaction). There are a lot of bugs, which may interrupt the user’s action (error). Sometimes, changing a small setting means to go to so many options which makes the system too complex (complexity/simplicity).
Digital cameras: Sometimes there are too many buttons that the user do not know the symbols on them. It’s might require a lot of time to learn it (learnability). And, as users turn back after a long time for not using them, they might forget the meaning of the icons (memorability).
Cell phones: Some times the font is too small to see it clearly (readability).
MP3 players: The buttons on the MP3 player are too close that users are prone to errors as they push them (error). Sometimes, to change a setting requires too many steps, which is not quite efficient (efficiency).
Accessibility Solutions
We have talked a lot about the problems of accessibility. Since accessibility means to make the product used by a wide range of people, the special needs of some groups of people must be needed. Therefore, we need to consider people with these impairments:
Visual impairment
Hearing and speech impairments
Cognitive problems and learning disabilities
Mobility impairments
So, what are the solutions to those problems?
Here is my presentation about the solutions to the 3rd and 4th problem.
Intelligent Machines and Foolish Humans. Retrieved from AI Research
As technology develops in an unprecedented speed, machines are growing more and more intelligent, thus blurring the border between human and machine. Therefore, moral, ethical, social, economic, and environmental problems rise due to the more advanced machine.
Before talking about these problems, I would like to clarify the difference between moral and ethical issue:
Regarding this these issues, I will narrow my topic to one technology: Visual Reality. Here is my presentation (click to see bigger picture):
To conclude this blog post, I would like to add one TOK question. Is VR an ethical technology? In my perspective, there is no exact answer. I think that VR is kind of neutral. It depends on how human will use it. I believe that it will bring us to unimaginable future.
These weeks, we are learning about the internal assessment of IBDP. The CS IA generally requires us to be a developer of a software and to create a product eventually. The whole process is assessed according to the criteria from IBCS.
Criterion A: Planning (5-6)
There are three parts in the planning stage.
Defining the problem or unanswered question
Justification for the proposed product
success criteria
Firstly, we should depicts the scenario of the problem, which includes the consultation with the client. The second part is rationale for solution, which is a brief outline of how my product will solve the problem as well as the reason why I choose the specific programming language. The success criteria guides me to evaluate my product, which includes 5-7 bullets points.
It must be noted that the first two parts are between 175 and 200 words each, and the success criteria are listed as bullet points, which is not included in the word count.
Before the planning stage, we should give Mr. Pete our IA proposal. The proposal should specify the problems of the old system as well as the solutions for them and the requirements of the new system.
Criterion B: Solution Overview
The solution overview actually belongs the design stage of the system development. It includes:
Record of tasks
Design overview
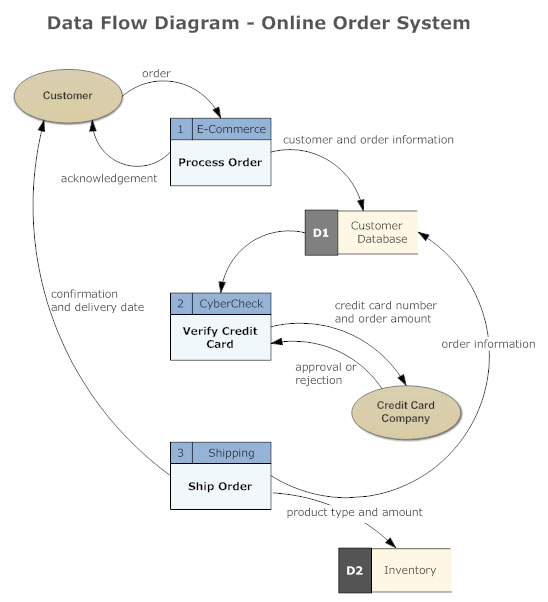
A data flow diagram may be included in this stage. Retrieved from smartdraw.
The record of tasks (ROT) file, which includes some significant steps of developing some criteria. The design overview includes the test plan, the brief summary of methods, and the design of the solution (through flowcharts and other graphical visualization).
Criterion C: Development
In this stage, the different techniques and algorithms used should be appropriate and should be identified and presented. Also, we should show the reason why we use certain techniques, using screenshot to illustrate our thinking. It is also very important to cite sources correctly using MLA format. This development document should be approximately 1000 words.
Criterion D: Functionality and extensibility of Product
Criterion D involves two parts:
Evidence of functionality
Extensibility
To make sure that the product is functioning, the product needs to be tested using the success criteria. Also, the product needs to be tested in several locations, meaning that it should be tested on a DVD or USB. As long as the product functions well, a video should be recorded to show how well the product functions.
Moreover, the ways that the product can be further improved should be included. Also, we should specify how a third party would maintain the product.
Criterion E: Evaluation
The evaluation section should involves:
Evaluation of the product
Recommendations for further development
Feedback from the client and advisor. Retrieved from Nepalipaisa.
As developers, we need to collect the client’s and advisor’s feedback, and link them to the cover page. Also, the product should be evaluated based on the success criteria in stage A as well as the feedback we obtained.
Furthermore, specific and realistic studentrecommendations for the improvement of the product should be included.
Usability
As a crucial part in user experience design, usability is the potential of a product, app or website to accomplish user’s goal. Generally, a program of high usability is easy to use and is self-explanatory. The three main elements of usability are effectiveness, efficiency, satisfaction. To improve a product’s usability, one must consider the users’ needs, wants, and abilities from the perspective of actual persons.
Here is a video for you to understand the concept better.
Ergonomics & Accessibilities
Ergonomics and Accessibility are two components of usability.
An applied science concerned with designing and arranging things people use so that the people and things interact most efficiently and safely —called also biotechnology, human engineering, human factors.
The goal of ergonomics is to optimize human well-being and performance of the system when human uses it. For example, the angle between the Macbook’s screen and the keyboard can be adjusted so that people can see the screen clearly in different body positions. This is a design related to ergonomics.
Here is a poster made by my classmate that demonstrate what is ergonomics:
For accessibility, the main goal is to meet the needs of as many individuals as possible (i.e. handicapped people or people with specific needs). For example, there is a setting in iPhone called Accessibility under the General setting. There are settings about reading the text so that people who cannot see clearly can access the information in this iPhone.
The design stage is usually regarded as the second stage of the system development life cycle. In this stage, how the system is created and how the system operates will be designed. Below are several ways to illustrate the system graphically.
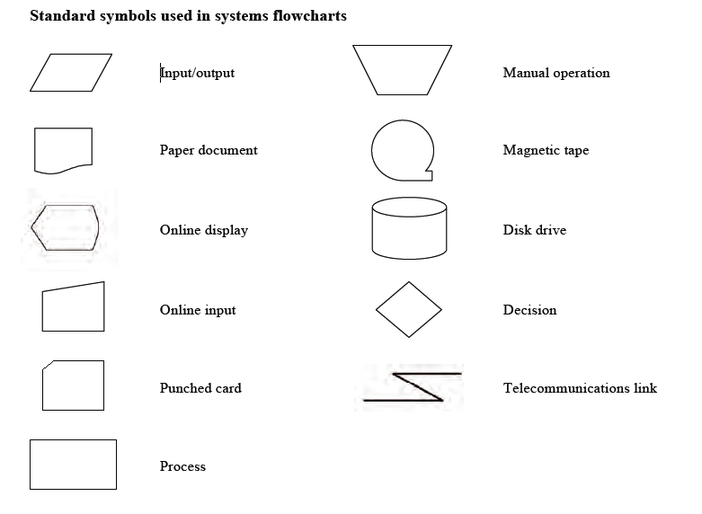
System Flowchart, DFD and Structure Chart
These three are three types of illustrations of the design of a system. The words that are bold are key features of each illustration that distinguish them apart.
The system flowchart shows how the system generally work. It illustrates the relationship and connection between different parts of the system, as well as how the data flow between these parts. The data storage type is also shown. However, details are excluded from the flowchart.
It shows the route and direction of data flow with a system. It focuses on inputs and outputs to the system. It is used to describe the problem to be solved. It seems similar to the system flowchart, however, it focuses more on how data flow from process to process.
Functions and sub-functions; Relationship between the modules
No arrow
Relationship of the modules
Break large problem, make it easier for the system analyst
Types of Processing (presentation)
The followings are the types of processing. The pictures are from the presentation addressed by David and Justin.
Online Processing (interactive)
A process in which the user directly interacts with the system.
Real-Time Processing
A subset of online processing since there is no delay between the input and the change in the system.
Batchprocessing
A series of non-interactive jobs all at once
Prototype
Prototypes represents the system abstractly by focusing only one or two key aspects of the system. For example, a prototype can be the “ghost” user interface which does not include any central complex algorithms.
By having prototype, we can test the system before implementation. Also, prototypes help the developer to show to the client what the product will be like. Therefore, customers are usually attracted by the prototype and continue to invest more into the project.
Here is a real life example of the use of prototype.
Let’s assume we are designing a robotic system. The robot is going to be used in a automatic restaurant. Now the restaurant really wants to see the product as soon as possible, since the restaurant wants to make sure that the robot is suitable for the service system in the restaurant. The robot is easy to produce, and it can be mass produced.
In this case, a prototype is necessary.
However, sometimes we might not need prototype. Also for a robotic system, if the robot is going to work in very dangerous environment, it’s very hard to replicate the environment for testing the prototype. Then, it might be better to produce the product directly. Also, if some products can be tested through simulation, making a prototype is not necessary.
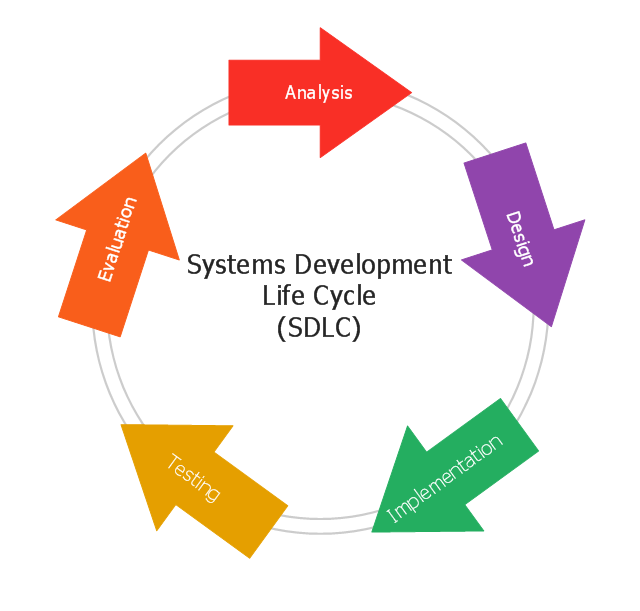
The System Development Life Cycle (SDLC) generally includes five phases:
Analysis
Design
Implementation
Testing
Evaluation
This five phases are called a cycle because there might not be a final product at the end of one cycle. Then I will discuss these stages in detail.
Analysis
Before developing a new and better system, we should first learn about systems that are already exists. We should firstly know “what is wrong about the current system.”
Then, how to get information about the current system?
Methods of Gathering Information from Existing System
First, we can do interviews. It’s a direct way of getting the raw data from the stakeholders of the current system. By interviewing operators, supervisors, or managers of the current system, we can know what the problems are, what they require from a new system.
To specify how the interview works, there are two types of interviews: Structured Interview and Unstructured Interview. For structured interview, the questions are predefined and are presented in the same manner to all interviewees. In contrast, unstructured interview allow interviewees to freely express their thoughts and personal feelings.
However, interview is a way of getting the first feeling of the problems of the current system, and it is very time consuming. Also, some details might be skipped in the processing of getting information from interviewing.
So we can do direct observation. In this way, professional system analysts may walk around the organization and try to see how the staff work as well as their working practices. How can the efficiency of the system be improved? From observation, we can get the first hand and unbiased information about the current system. Also, we may notice many details which may point out the bottle neck that the current system has. However, it is also very time consuming to directly observe, and people may not work like they normally do if there are people observing.
To get a wider view, we need quantitative data. Questionnaires is a very good way of getting a huge amount of data. Questionnaires or surveys are cost-efficient and time-saving, comparing to the the previous methods. However, it also has its limitations, since it is hard to ask the right question, and the information is limited by the content of the questionnaires. Additionally, people who fill in the questionnaires may not take it seriously.
There are also two types of questionnaires:
Closed or restricted questionnaires only allow “yes” or “no” answers.It is good for statistical analysis. Open or unrestricted questionnaires includes free response questions. It allows people to express their deeper thoughts, but the answers are difficult to interpret.
The final method is the examination of documentation. Systems analysts will look in the documents in the archive of the organization and find out how the current system operates. The documentation includes reports, guidelines, or planning documents used by the organization. The advantage of this method is that, we can get very detailed information about the current system. Therefore, it is usually used in the process of system analysis.
Design
Analysis is all about the current system, while design is about the new system.
The process of designing determines how to create the new system and how it will operate. The design should not be like a “screenshot” of the real program. Instead, the design should be a general layout of the program.
The process of design involves three or four parts. The first one is user interface. The second part is the process of developing the program. The third part is about the data storage requirements of the program. If there is a fourth part, it should be test design, which designs the how the test will operate.
Here is an example of test design. which should be filled out at the design stage (except for the actual outcome, which will be filled during the test).
#number
Short Description
Input data
Expected outcome
Actual outcome (leave it blank)
F. #.
F. 1.2
Implementation
Implementation is the process of really getting to create the program. It might involve creating or installing the hardware, but it is not required for IB IA.
In the implementation stage, software and maybe hardware is installed. Also, data files are prepared and users are trained. Also, it involves writing the system documentation, which is the documents that specifies how the system works.
And at the same time, system developers should make sure that the system that they build fits in with what they designed.
Testing
In general, there are three types of testing.
Black box testing: Only look at the input and output without testing the inside of the program
White box testing: Not only do we look at the input and output, but also we look at the inside of the program.
Dry run testing: looking at each instruction step by step.
The dry run testing is the most tedious and time-consuming one. However, it is usually used because of its strictness – no error should be skipped.
Evaluation
Evaluation is the process of reflecting on how successful the operational system is. We can ask questions like:
Does the new system meet its original system objectives and requirements?
How effective is the new system in solving the original problem?
If the answers are negative, the system should be analyzed and improve. Even if the system meets the standard or requirement, there should always be a recommendation of further improvement.
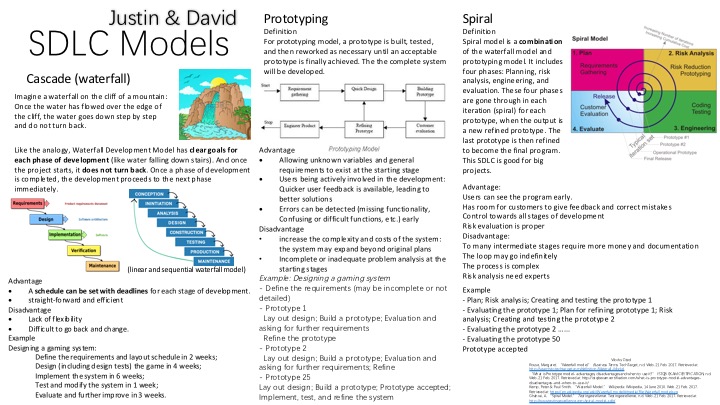
Group work: Development Models
Here is a poster that we made that demonstrates the three development models.
Stakeholders & End-Users
Stakeholder are people who have an interest or concern in a project or something about the project, or they are individuals, teams, groups or organizations who might be affected by the outcome of a project.
Stakeholders can generally be divided into two types:
Internal
Employees
Manager
Owners
External:
Suppliers
Society(community)
Government
Creditors (like ibo)
End users are people who will use the product of the project. Therefore, a stakeholder might be an end-user at the same time.
The role of the end-user must be considered when planning a new system
This sentence stresses the importance of considering the role of the end-user so that the program will meet their needs.
When developers develop a product, there are 3 important questions:
Who will the end-user be?
What are their needs?
Any other stakeholders?
Answering these questions will help the developer create programs that most of the important people like.
Besides, there are some parties that are usually involved in a System:
System analyst
End user
Software manufacture
Client company
Actually these parties are all stakeholders of the product. When we do the Internal Assessment, we should definitely consider these parties and communicate with them.
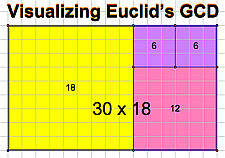
The oldest algorithm is Euclidean Algorithm, which is used to calculated the greatest common divisor of two integers. Here is a picture illustrating how it works, which I will talk more about later.
In this documentary, there are many more complex and interesting algorithms. Here, I chose seven of them to introduce algorithm in detail.
Euclidean Algorithm
As explained in the introduction, the Euclidean Algorithm is used to calculate the greatest common divisor of two integers. To visualize the mechanism behind the algorithm, we should look at the picture shown above. The two sides of the rectangle are the two integers that we are going to use to find the greatest common divisor. To begin, we use the shorter side as the side of a square in the rectangle. Then we took out the square, and do the same thing to the remaining rectangle. Eventually, the remaining rectangle can be perfectly divided to several squares, and the side of the square will be the greatest common divisor. This looks magical, but the basic principle is that the common divisor of the smaller number and the difference of two numbers is the same with the initial common divisor.
Through the lens of this old algorithm, let’s learn more about modern algorithms which are more complex and interesting.
Google Page Rank Algorithm
The google page rank algorithm is the first incarnation of the Google search engine, which is also the algorithm that made Google stood out.
The basic idea of this algorithm is that pages are ranked according to the inbound links that one has. Suppose that page C has its link on page T. The benefit that C can get from being linked by T depends on the rank of T and the total number of the links on T. (Reference: efactory) Also, there are also other factors that affect the ranking, which are just little complex.
This algorithm make it possible for users to find the most related and highly rated sites that may save a lot of time and efforts. With the development in computer technology, this algorithm can reduce human work as well as improve the efficiency of information searching.
Sorting Algorithm
Sorting algorithms are primarily used to line up a list of values from small to large (or from large to small.) The three basic algorithms that I am going to talk about are bubble sort, select sort, and insert sort.
Bubble sort is the simplest method of sorting. However, it is usually considered as the slowest for a large amount of value. Suppose that there is a series of values, bubble sort compares the first two values and switch them if the second value is less than the first one. Then, we do the same thing to the second and third value, so on and so forth.
Select Sort
In this sorting method, the data set is scanned, and the smallest value is found at first, and this value switched with the first value of the set. Then, in the second scan, the first value is fixed. The smallest value of the remaining values is then selected and switched with the second value of the whole set. This required time for this sorting method is usually predictable, but it is not very efficient.
Insert Sort
This sorting algorithm selects each value one by one, while comparing it with the all values before it. Then, the value selected is inserted in the right place – between a smaller one and a larger one.
Stable Marriage Algorithm
The stable marriage algorithm is a matching algorithm which match people who like each other. Now, over one-third of marriages are started online.
Suppose there are four girls and four boys each has his or her best choice to the fourth choice. Firstly, we just put the put the girls next to their first choice. Then, if there are more than one girls choosing one boy, the girl who has the highest ranking in the boy’s viewpoint is reserved, and others are then put next to their second choice. Eventually, they are all paired up.
I think this algorithm is extremely beautiful since it basically creates the most stable relationships. Moreover, it can also be used in other fields, such as organ donation matching.
Shortest Route Algorithm
In many real life situations, people need to find the shortest route to go though several places. For example, a postman wants to deliver all the mails to different places in the shortest time, but when there are too many places, it is very hard to find the shortest route.
To create an algorithm to achieve this goal, people tried hard but failed. Clay mathematics institute once offers 1 million dollar for whoever can find an efficient algorithm to solve this problem, or prove that none exist. The result was, mathematicians proved that the algorithm for this shortest route problem do not exist.
Using radar to record bumble bee’s routes. Retrieved from the documentary.
However, although we cannot find the most efficient way, there are some ways we can just find an adequate method. For example, some researcher found that when bees collect honey, their routes are quite efficient. They made models for the bees routing rule.
From this example, we can see that there is not always a solution for every problem. Algorithm is not the perfect tool, but it is useful enough and it indeed improves efficiency.
Heathrow Sequencing Algorithm
Retrieved from the documentary.
This sequencing algorithm is named after the Heathrow airport. It controls the departing time and route of all aircrafts in the airport. Since medium aircraft cannot depart next to a large aircraft because of the strong wind caused by the large turbine. Also, there is the problem of efficiency. Therefore, controlling the departure of airplanes is an extremely difficult task for human as there are too many factors. But machines can do calculations easily, as long as we tell them the rules.
This algorithm not only improves efficiency, but also save lives by preventing human mistakes. The high reliability of machines enable people to do something that seem dangerous or impossible in the past.
Machine Learning
Retrieved from the documentary.
Machine learning algorithms can develop themselves and learn from data.
For example, an algorithm can display people’s body movement in pixels of colors in real time. Different body parts are marked to different colors respectively. This algorithm is called decision tree, which ask twenty questions that help judge what body part it observed. The more examples it observe, the more accurate it is, the more questions it will ask – it writes questions by itself and make itself more accurate.
Machine learning algorithms are more flexible, having potentials to improve, even to a extent that people cannot predict. They relieve human from analyzing tons of data and looking for the clue.
To conclude, algorithms are steadily improving from past to now, from making human work easier to transcending the ability of human. I believe the algorithm, especially artificial intelligence which is based on machine learning, will bring human to great, unimaginable possibilities in the future.
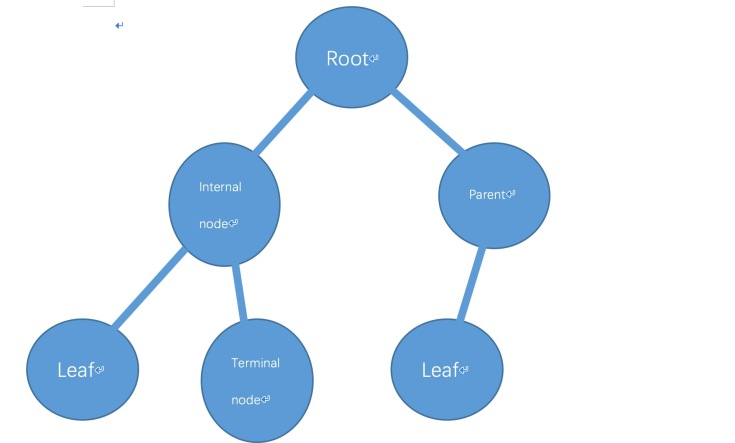
A rooted tree is an abstract data type which consists of nodes arranged in hierarchical order.
A picture I drawed using Word.
As the picture shows, the tree is like a tree reversed. The single node at the top is called root. Nodes that have nodes connected to it below is called parent nodes; the one or two nodes below a parent is called child node. If a node doesn’t have any child node, it is called a terminal node or a leaf.
Binary Tree
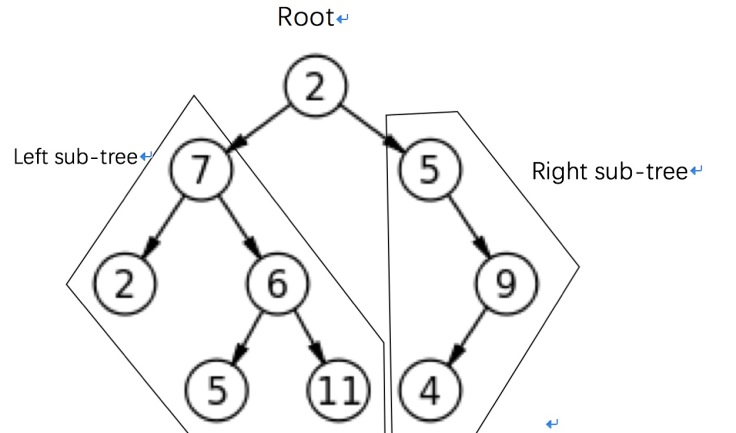
Given the concepts above, each parent in a binary tree has at most two child nodes – that’s why it is binary.
A binary tree can be divided into three subsets, or it can be empty, as shown above.
How Is Binary Tree Useful?
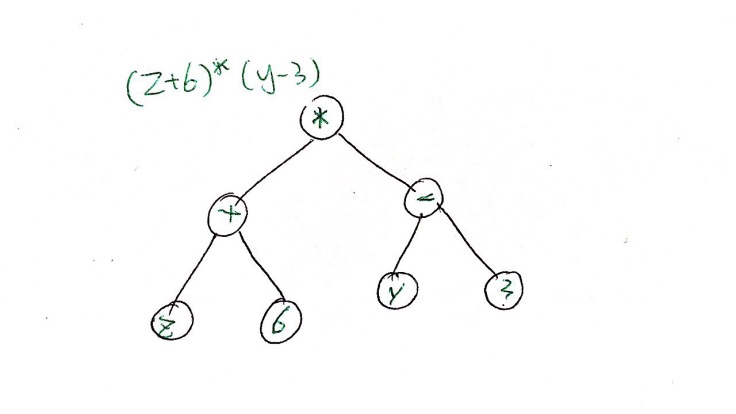
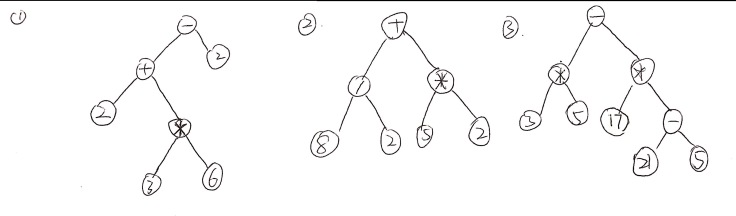
Firstly, it can represent the order of mathematical calculation. For example, brackets are calculated first, then the power, then multiplication and division, and at last addition and subtraction.
To operate this arithmetic expression, we should start from the bottom to the top and from left to right. The actual numbers are stored in the terminal nodes of the binary tree. Using this binary tree, the expression is presented unambiguously.
Retrieved from Mr. Pete’s presentation
This is a diagram that shows the binary tree as a data type. Each item is the actual value and is stored with two pointers which serve as addresses. If there is no child node below, the value of the pointer is zero.
Traversal
Tree traversal means to visit all the nodes of a tree in particular order. Here are three ways of traversing a binary tree.
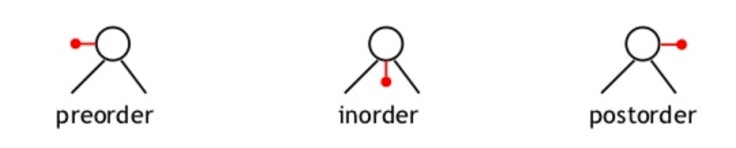
Pre-order traversal
The root is visited first
In-order Traversal
The root is visited in the middle
Post-order traversal
The root is visited at last
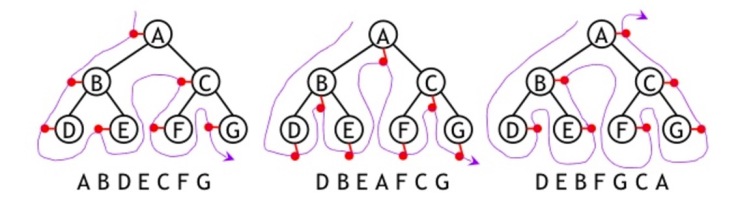
To illustrate the difference between these traversals clearly, we can imagine a flag on each of the nodes.
To visit the nodes in the correct order, we just need to follow the flags along the tree, as shown in this picture:
The steps for insertion operation is similar to the searching operation. We we found that the searched value doesn’t exist, we insert one.
Removal Operations
In a similar way, if we want to remove something, we first find it and then remove it. However, there are three situations:
When the node has no child: Just deleting it.
When the node has one child: Connecting the single children to its parent.
When the node has two children: Finding the minimum value of the right subtree and replace it. (Since the value of the node is the middle of the left subtree and right subtree.)
Linked List
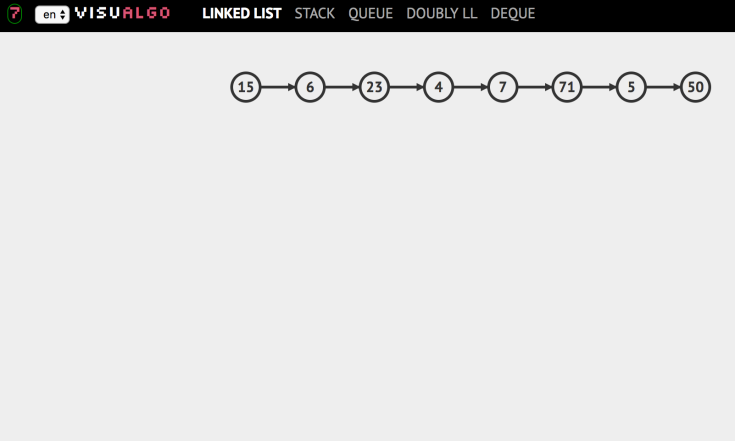
This website, visualgo, is very useful since it teaches you about many CS concepts and provides a simulation. After I tried binary tree, I explored linked list. Generally, there are five types of linked list. Single linked list has one-direction arrows while doubly linked list has two-direction arrows. For stack, we can only add, remove, search the head of the list. For queue, we can search the head value, remove it, or add new value to the tail. For deque, both head and tail can be added value, removed, or searched.
This blog post is a reflection upon Chapter 3 of our CS textbook. In this chapter, I learned many concepts about object interaction. I will also include some exercises that I have done while learning this chapter.
The clock example
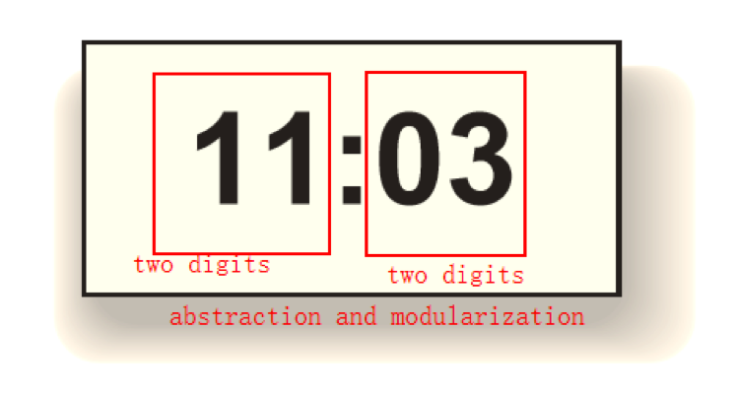
Abstraction & Modularization
To understand the meaning of the CS concepts, we use a typical example, which is electric clock, as the picture shows. This clock consists two parts (or three parts): The numbers on the left side of the semicolon, the semicolon, and the numbers on the right side of the semicolon. This program seems complex to us. Therefore, when we program, it is easier for us to break this “clock” into two parts. This process can be called abstraction, in which we ignore some details and focus on a higher level of the problem. The method of dividing the problem is also referred to divide and conquer.
After we break the problem into two parts, we need to deal with each part. To make each part works separately and interacts with each other well, we need the notion of modularization: “The process of dividing a whole into well-defined parts that can be built and examined separately and that interact in well-defined ways.” (definition from textbook)
Now we shall look at source code of the clock example. Since we have divided the clock into two modules, each of which is a display of two numbers. Therefore, we should first create a class called “NumberDisplay.”
We have two values to be defined, one is the actual number, the other is the limit of the number.
Then, to display the two numbers together, we need to create a class “ClockDisplay,” which makes use of the NumberDisplay class. Therefore, the results from NumberDisplay classes will become the fields of this new class. When this happens, we need to define the type of the variables as classes. This is called class define type.
As we can see, these two fields, hours and minutes, have class-defined type, so they can hold the objects of the classes.
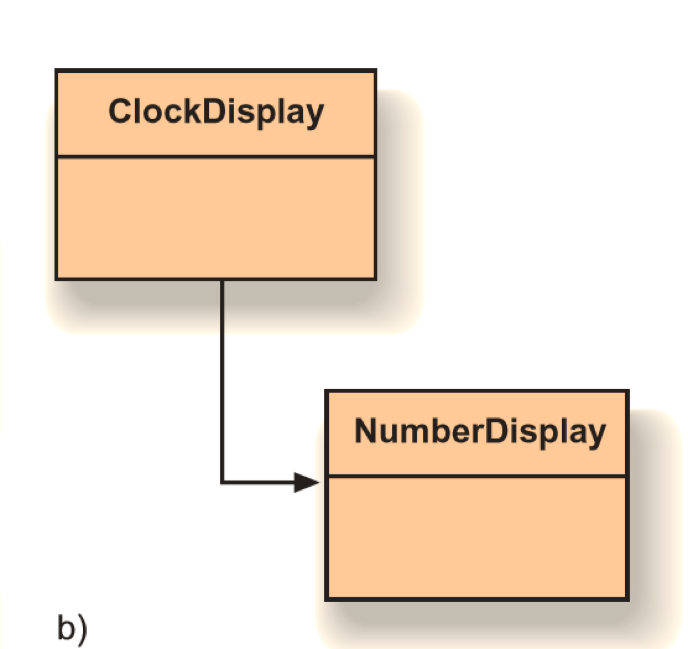
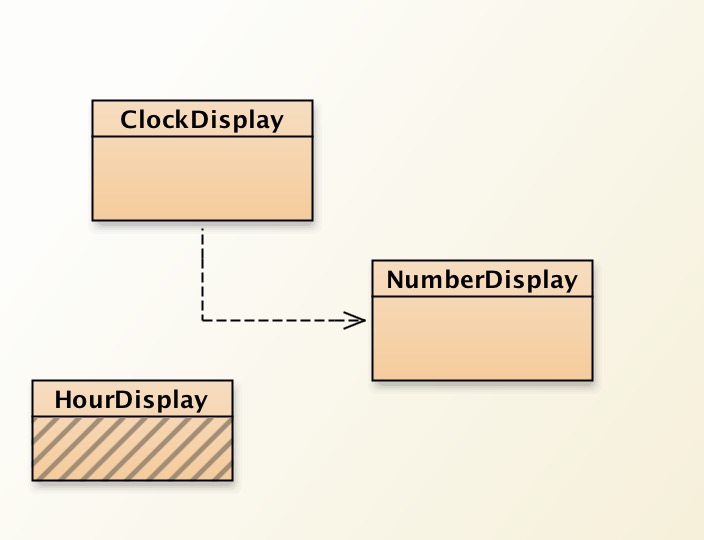
To visualize the relationships between class, we can draw a class diagram.
Although two objects of the class NumberDisplay are used in the class ClockDisplay, we can notice that there is only one class linked to the class ClockDisplay. This is because that although there are two objects, there is only one single class.
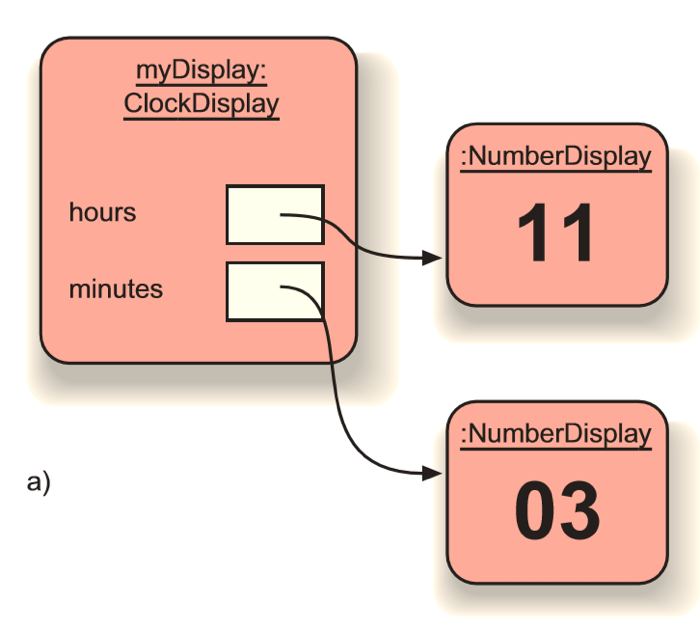
The object diagram is different, though. Since there are two objects used as states of the ClockDisplay object, there are two NumberDisplay objects.
Also, the meaning of the arrows in an object diagram is different from them in a class diagram. The arrows show reference to the object, meaning that the variables that have object type can only store the reference to the object; once the object is changed, the variable changes as well.
However, primitive data type is different from object type. Variables that have object data type is defined by class. There are 8 primitive data types, including boolean , byte , char , short , int , long , float and double. For primitive data type, the values are stored in the variable themselves, rather than storing the references.
Logic operators
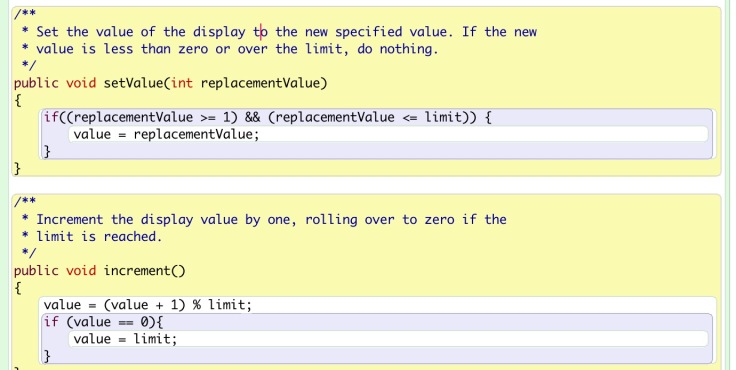
Now we shall shift our attention from the class and object diagrams to the source code. Firstly, let’s look at this picture.
This is the source code of the class NumberDisplay. The codes in this mutator method are used to make sure that new value added by the user is eligible for using. Here, the “&&” is called an logic operator, which means “and,” as what we have learned about logic gates. Additionally, “||” is “or,” and “!” is “not.” This is very useful when we write the codes for conditions.
String concatenation
We have learned about String concatenation before, and I have also posted a blog that introduces String.
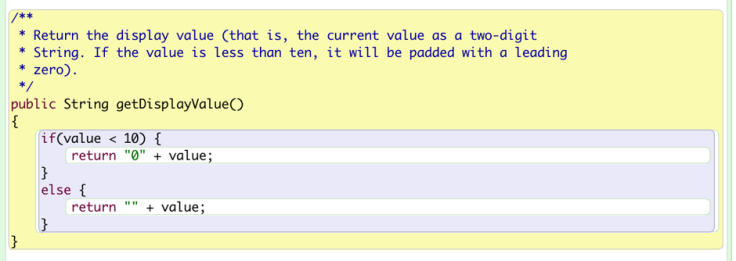
Here, the programmer uses String concatenation to make the number displays in a correct way.
Since the number might have two digits or only one digit, and we know that there are always two digits for the minute or hour section of a clock, we should add a “0” before the value when the value is an one digit number. Also, to change the type of the value from int to String, I concatenate a null String “” to the value. This is a very smart way of changing the type of the value.
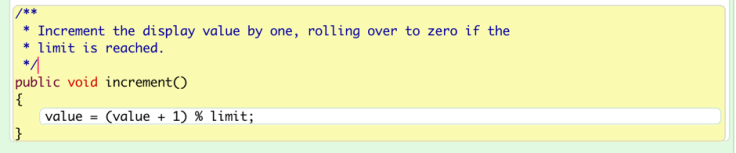
Modulo
There is another operator that is pretty useful.
Here, the “%” is modulo operator. It functions firstly as a division operator, but it returns the remainder of division.
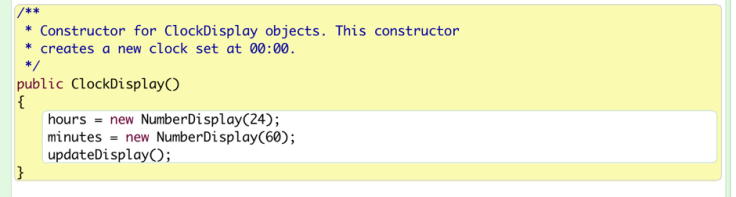
Object Creation
Now we shall look at the ClockDisplay class. The class NumberDisplay we have discussed about is used to display two digits. Noted that the parameter for the numberdisplay object is the limit of the two-digit number.
Let’s see how the ClockDisplay method makes use of the NumberDisplay class.
Firstly, two of fields of the class – minutes and hours – are class defined type.
Therefore, the object of this class will automatically create two different objects from the class NumberDisplay.
Then, in the constructor, the two objects are created using the parameters “24” and “60.” From this example, we can see how objects from the same class can be different, and also we see how objects creates objects.
Overloading
It is not hard to notice that there are two constructors in the ClockDisplay class.
This is known as overloading a constructor. When the object of this class is created, the user can choose from these two constructors. The second one calls the setTime method defined in the NumberDisplay class, which does let users to change the value stored in the number displayed.
The second one does not change the value of the both numbers, which are set as zero in the constructor of the NumberDisplay class.
Method Calls
There are two types of method called used in this program. The first one is “internal call,” through which a method that is in the same class is called. For example, the method call shown below is an internal call.
This method is defined in the same class.
Internal call follows the format of “method name (parameter set);”.
In contrast, there are external calls.
In the picture, the method “setValue” defined by the NumberDisplay class is called, which is not from the same class as these codes. The syntax of an external call is “object.method(parameter-list)”.This syntax is called dot notation. It shows that the method is acted on the another object.
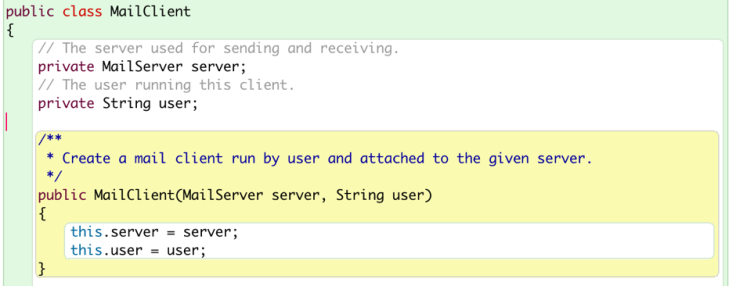
This Keyword
We can see that the variables “server” and “user” are defined in the fields. However, they are used as the parameters of the constructor. Can this work? How does the computer distinguish the fields and parameters? The answer to the first question is yes, but to distinguish them, we need to use the keyword “this” to specify the field variables. The syntax is “this.variableName”. This is very useful since we can just use the name of the fields to label the parameters.
Challenge Exercise
To complete this exercise, not only do I need to change the NumberDisplay class, especially the codes that use modulus operator, and also I need to change a parameter in the ClockDisplay class.
Actually, since minute display is different from hour display, I created another class, named HourDisplay.
I copy the codes from NumberDisplay, and then do the following changes.
Firstly, in the constructor, I changed the argument “24” to “12”.
Then, since the number of hours become 1 to 12 instead of 0 to 23, I changed the condition of the parameter replacementValue to a range from 1 to limit. Then, I add an if conditional statement to change the “zero” to the value of the limit.
The HourDisplay class
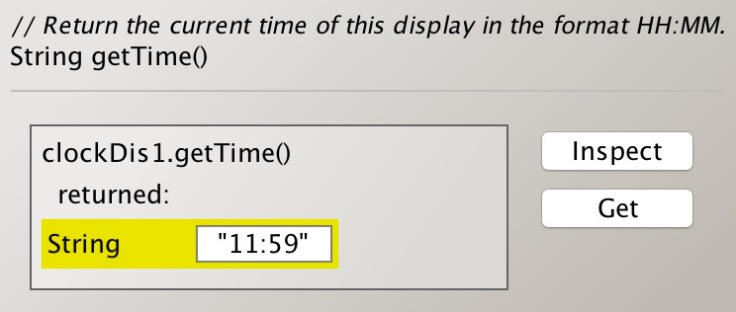
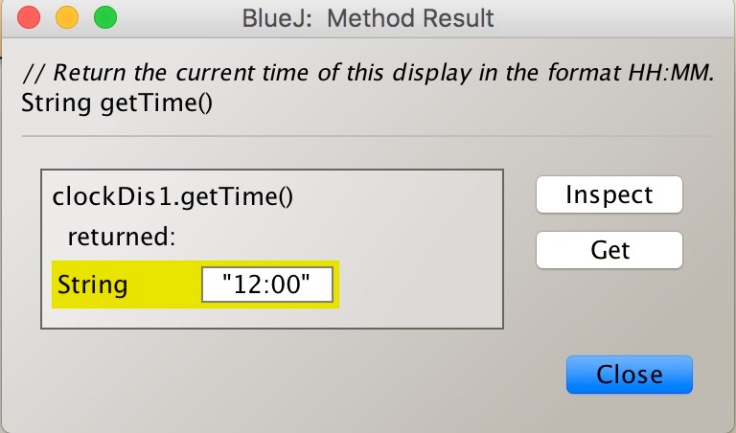
At last, I check if the clock works. I set the time at 11:59. If the clock tick, it should become 12:00. Let’s see!
In this post, I will include the major concepts and exercises of Chapter II of the textbook OBJECTS FIRST WITH JAVA A PRACTICAL INTRODUCTION USING BLUEJ (5TH EDITION). Also, I will explain then and also reflect upon them. The main terms I will discuss about are the followings: Fields, methods (accessor, mutator), constructors, assignment and conditional statement, and parameters.
Before that, I would like to share the 9 exercises that I’ve done in class.
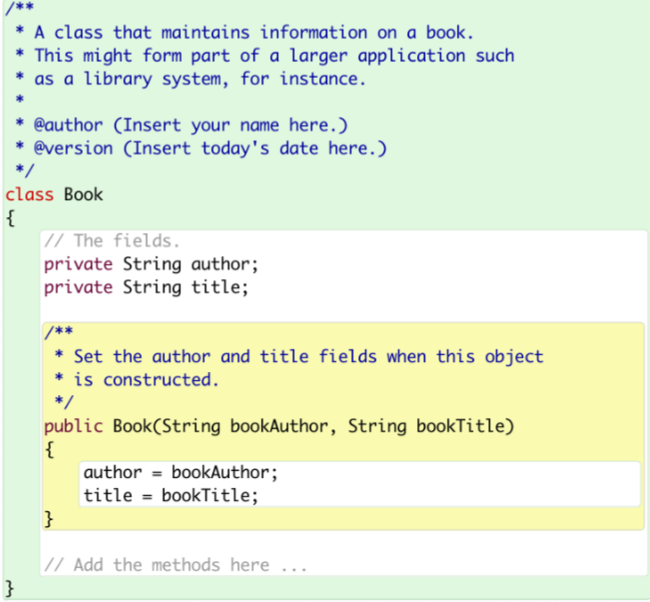
We were given these code beforehead. I created a class named “class,” and I type in these codes.
Exercise 1
This exercise asks me to create two accessor methods. The user can use these methods to get the information about the author as well as the title of the book.
Exercise 2
This exercise asks me to create two methods that can print out the author and the title of the book. These two methods are different from the previous accessor methods, since they do not return any value, as we can see from its signature “void.”
Exercise 3
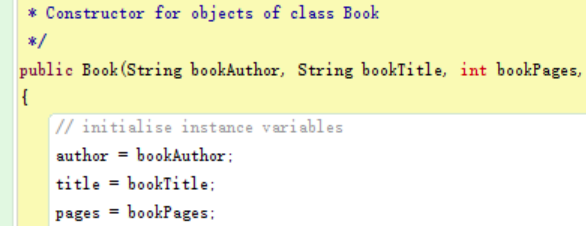
I first create a new field “pages,” whose type is integer.
A new field.
Then, I add a parameter in the constructor to enable the users to initialize the value of this field.
constructor
Then I created an accessor method which can get the value of the field “pages.”
An accessor method.
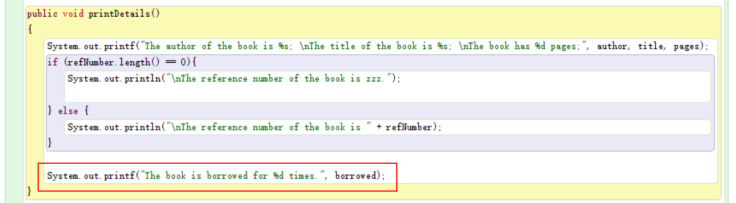
Exercise 4
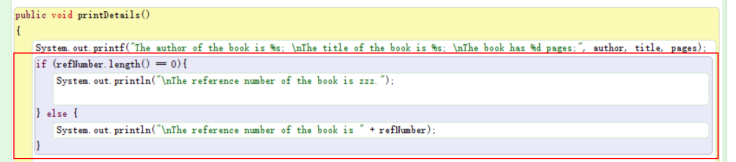
I add a method that can print out the state of the object created from this class book. I used printf method to do it in an easier way.
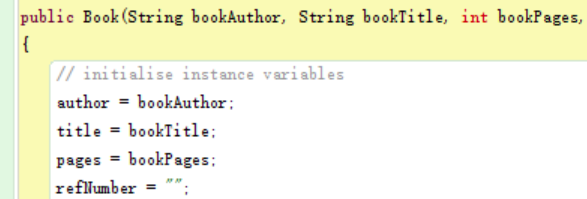
Exercise 5
This exercise asks me to create a new String field “refNumber,” which is a number that can be set by the user to label the book. Additionally, I created an accessor method to return the value of this field.
Since I took the screenshot after I finished all the exercise, I crossed out the unrelevant codes.
Exercise 6
The if conditional statement checks if the field “refNumber” is assigned a value. Also, the method “.length” is used to check if the String has an empty value.
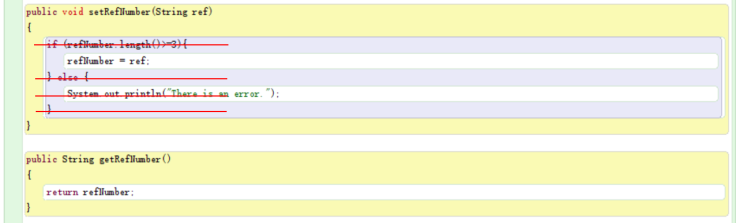
Exercise 7
This mutator method makes sure that the refNumber is assigned a String value that is not shorter than 3 characters.
Exercise 8
This time I created a new field called “borrowed”. I created the correspondent accessor method as well as the set mutator method. Then, I add “borrowed” to the printDetails method.
The mutator method add 1 to the field “borrowed” each time it is called.
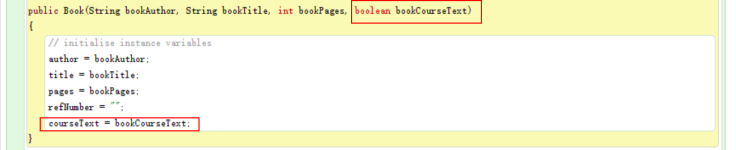
Exercise 9
This time I created a new boolean field named “courseText, which shows if the book is a textbook or not. The value of this field is initialized in the constructor, and it cannot be change through any mutator method (since I did not write such method), we can call it immutable.
Chapter II
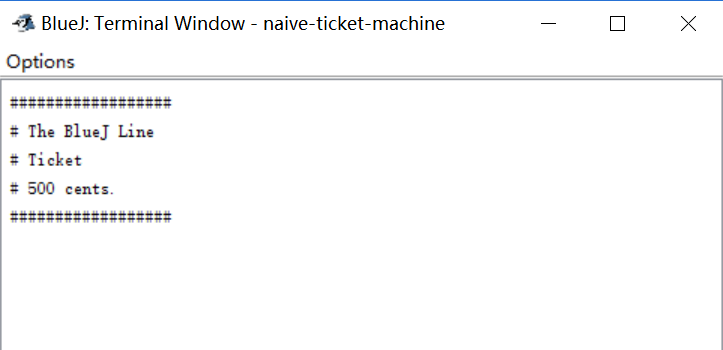
Naive Ticket Machine
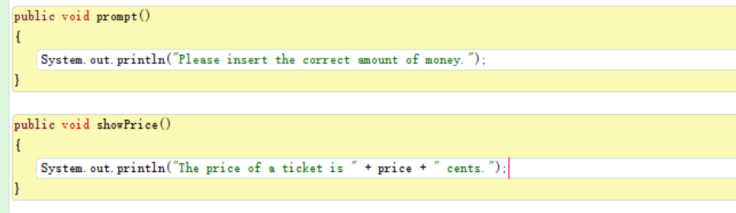
This ticket machine can “get money” from the user, print the ticket, and record the balance. First, I created an object of the class.
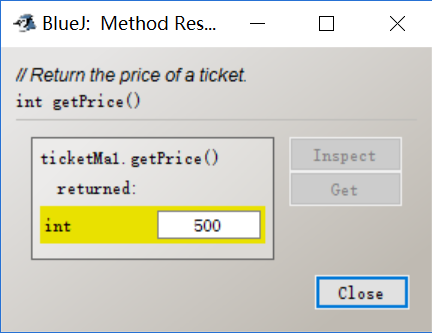
I created an object from the class “Ticket Machine” and set the price of the ticket as 500 cents.
By calling the getPrice method, I can check the price of the ticket.
Then I inserted 500 cents into the machine, and I printed the ticket.
This is a simulation of a real ticket.
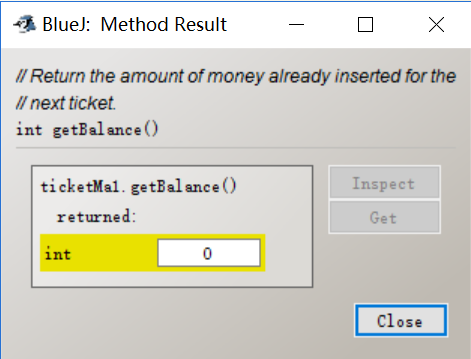
After I printed the ticket, I checked the balance which became zero.
However, there is problem, if I insert 600 cents, the machine will not give me refund. And the balance after the ticket is printed is still 0.
After playing around with this naive ticket machine, let go back to the source code of this class.
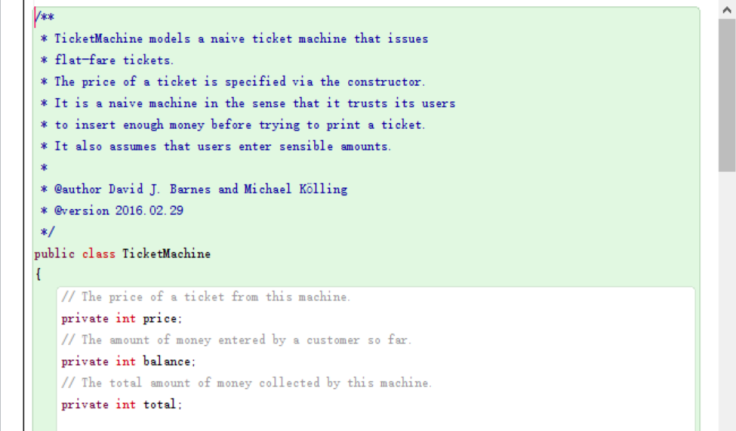
Part of the source code of the class “Ticket Machine.”
The whole program starts with a line starting with public class …. This line is called “class header.” Public defines if the program is public or private, and the word class defines this program as a class. Conventionally, the name of a class usually starts with an uppercase letter (Here the name defined by the programmer is “Ticket Machine,” and the “public cllass” belongs to java language).
Fields and Constructors
Retrieved from the Textbook
This picture shows the general structure of the source code of a class. Under the class header, there are three essential parts: fields, constructors, and methods. The order of these three parts can be changed, but I chose to arrange them in this order. Let see the source code of the ticket machine to better understand these concepts.
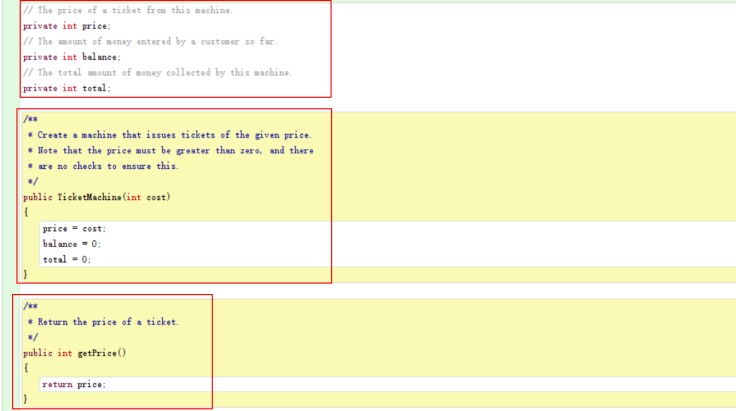
The codes in the first red rectangle are the fields. The fields usually start with the word “private;” then the type of the vairable, such as int, string and so on.
The constructors are in the second red rectangle. The constructor initialize the value of the fields by assignment statements. The header of the constructor include a parenthesis in which there is two words “int cost.” This is the parameter defined for user to assign value. The word “int” defines the type of the parameter, and the cost is the named of the parameter. We distinguish the parameters and their values by refering to the variable “cost” as a formal paramter, and refering to the the value, let’s say, 500 (if we input 500) as the actual parameter. The body of the constructor consists assignment statements, for example, “price = cost.” This assignment statement assign the actual parameter to the field price.
For example, I assigned the parameter a value of 500.
However, the formal parameter can be accessed only in the section of the constructors. In anywhere outside the constructor section, the parameter will be nothing. We say the scope of the formal paramter is restricted to the body of the constructor in which it is declared. In addition, another concept related to scope is the lifetime of a variable. For the formal parameter “cost,” its lifetime is restricted to the constructor section. When the constructor is called, the program creates space for the constructors. When it is done, the space will disapear and the formal parameter also disapears. However, the lifetime of the fields is as same as the lifetime of the object.
If a field is not defined in the constructor, it will be assigned a default value, for example, for integer, the value if zero. But when I am programming, I choose to set all the fields in the constructor.
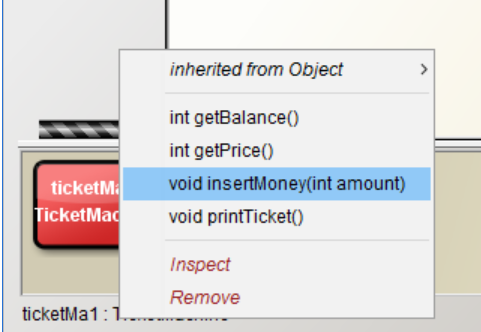
Methods: Accessor and Mutator
There are two main methods in OOP. The first one is accessor method.
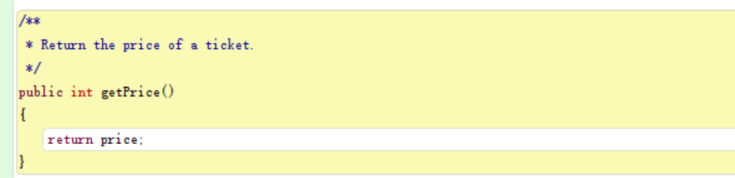
The getPrice method which return the value stored in the field “price.”
This method is an accessor method since it return the information about the state of the object.
It is better to know that returning value is different than printing out the value.
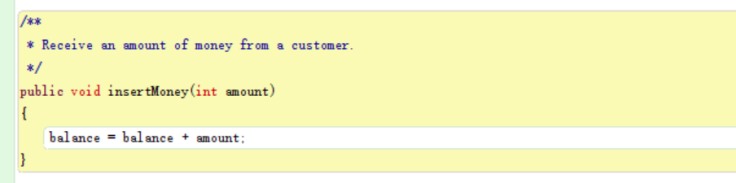
Here is an example of another type of method.
It’s easy to notice that the header of this method is different from the previous example. This method do not return any value back to the caller of the method. It’s return type is void.
This method is called a mutator method, or a mutator. It is used to change the state of the object.
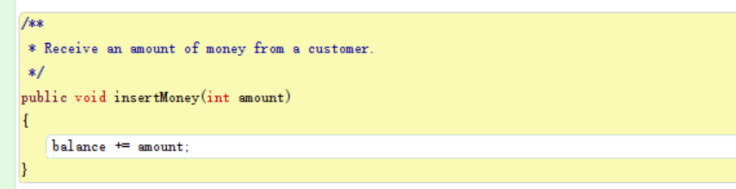
In addition, to make it easier, I used a useful tool called compound assignment operator to simplify it. Here’s the codes.
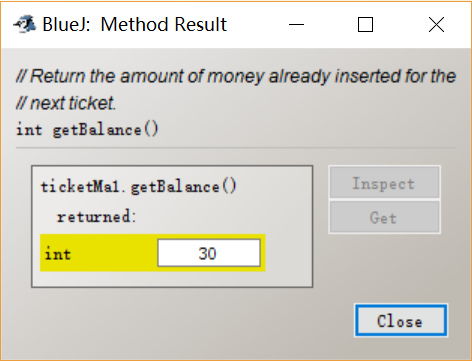
After I inserted 30 cents into the ticket machine, I called the getBalance method and get 30 returned. Then I inserted 30 cents and called the accessor method again, the value returned is then 60 cents. We can see that the insertMoney mutator method change the state of the object.
Here is my code for an exercise which asks me to write a mutator called setPrice.
This method can change the value of the field “price.” I tried to use it to set the price to 400 cents and then use getPrice, and I get 400 returned.
Except accessors and mutators, I can add methods that can print out something. For exmaple, here is the screenshots of the two exercises I have done.
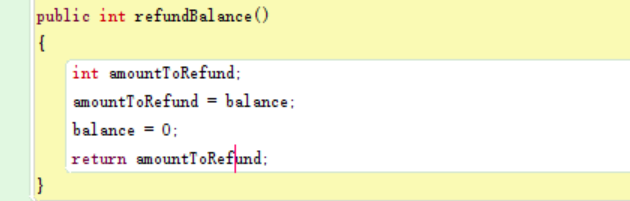
Local Variables
A local variable is a variable that is declared inside a method, which has a scope and lifetime limited to that of the method.
method “refundBalance” from object instantiated from the class “TicketMachine”
In this method, the integer variable “amountToRefund” is a local variable. If we want to use field instead of local variable, we may want to write like the following picture.
However, if we compile it, we will find an error. This is because that a return statement can only be operated when there all the statements are run in a method. Therefore, the return statement should always be written in the end of the method.
Work Cited
Barnes, David J. and Kölling, Michael. Objects First with Java. 2012, New Jersey: Pearson Education, Inc. Print.
A programming paradigm is a way or style of programming. Different programming languages are easier to be programmed in certain programming paradigm. There is no such a thing called prgogramming language paradigm, but we can call java as an object-oriented programming language.
Object-Oriented Language (OOP)
Objects and Classes
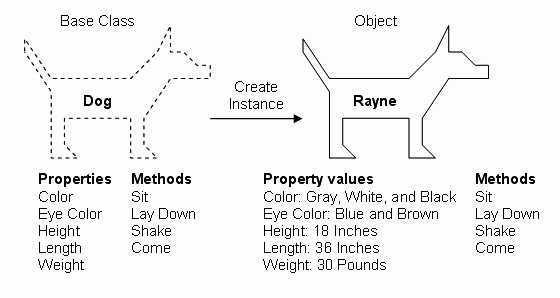
For OOP, class and object are two core concepts. First, we need to know what is an object. As an analogy, a car is an object, which has a set of attributes. For instance, there is red car which max speed is 150km/h, and its height is 1.6m. We can know exactly its attributes, and even change them. The specific car is called an object.
However, this object doesn’t come from nowhere. It is created as a car, not a bicycle or a tank. It belongs to car class. Yes, “car” is a class. We creat the car objects from “car” class. All cars objects have their maximum speed, color, and height, since these attributes are defined in the class “car.” These attributes are the fields of a class.
Here is another analogy which may help you to understand the core concepts of OOP.
RanMo
Exercises
The followings are some screenshots of the exercises I have done to understand OOP, as well some explanations of them. You will learn more concepts in these exercises.
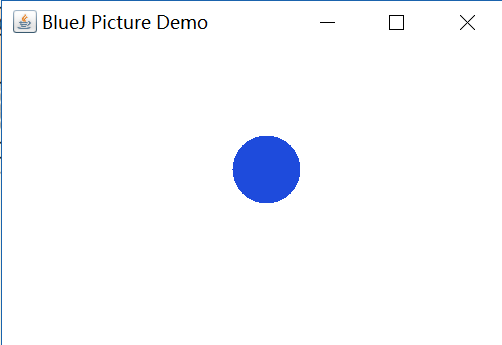
The picture on the left is the project named figures. The blocks are all classes. From circle class, I created a new object, named circle1. The picture on the right side shows the object in the corner of the object bench, where objects can be found.
Here, the object “circle1” we created is called an instance of the class “circle.” This process of creating an object from a class is called “instantiation.” It seems weird, but it is a term for CS = ̄ω ̄=.
circle1 and circle2: Two instances.
There are multiple instances we can instantiate from the class.
There is a pop-up menu if you right-click on it. There are several operations. These are the methods we can call in order to interact with the object. First, I tired the method “void makeVisible().”
The circle after being moved.
The window showed up after I invoked the “makeVisible” method. Then I tried moveLeft and moveDown for several times, as the second picture shows.
These operations are methods defined in the class. Let’s see the definition of method in the textbook (Barnes):
We can communicate with objects by invoking methods on them. Objects usually do something if we invoke a method.
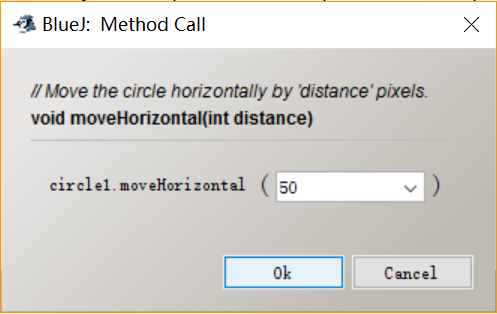
Method call: moveHorizontal
From this picture we know that what we are doing is called “method calling.” This method is asking the user to type in the distance that the circle moves. Here, the “distance” is the parameter of the method.
source code of the method void moveHorizontal(int distance).
Here is the source code of the class. The header of this method is called signature. It defines if the method return value or not, by writing the word “void” or not. Void means nothing, showing that the method does not return any value.
I assigned a value 50 into the variable “distance.” The type of this parameter isinteger, so we can only type in an integer.
As another example, this method is used for changing the circle’s color. The type of the parameter of this method is “String”, thus, I can only input a String value, which is “yellow” (Since it is string, we need to use quotation marks).
inspect window
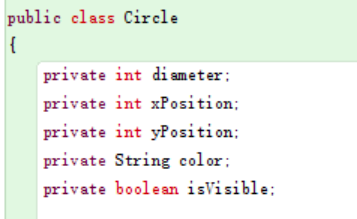
We can use inspect to see the state of the object. In OOP, these attributes are called fields, and the state of an object is the values of the fields.
There are five fields in the circle class. These fields belong to different types of data, such as integer, String, and boolean.